Stay updated with our letter
Valuable perspectives on the latest trends and tips.

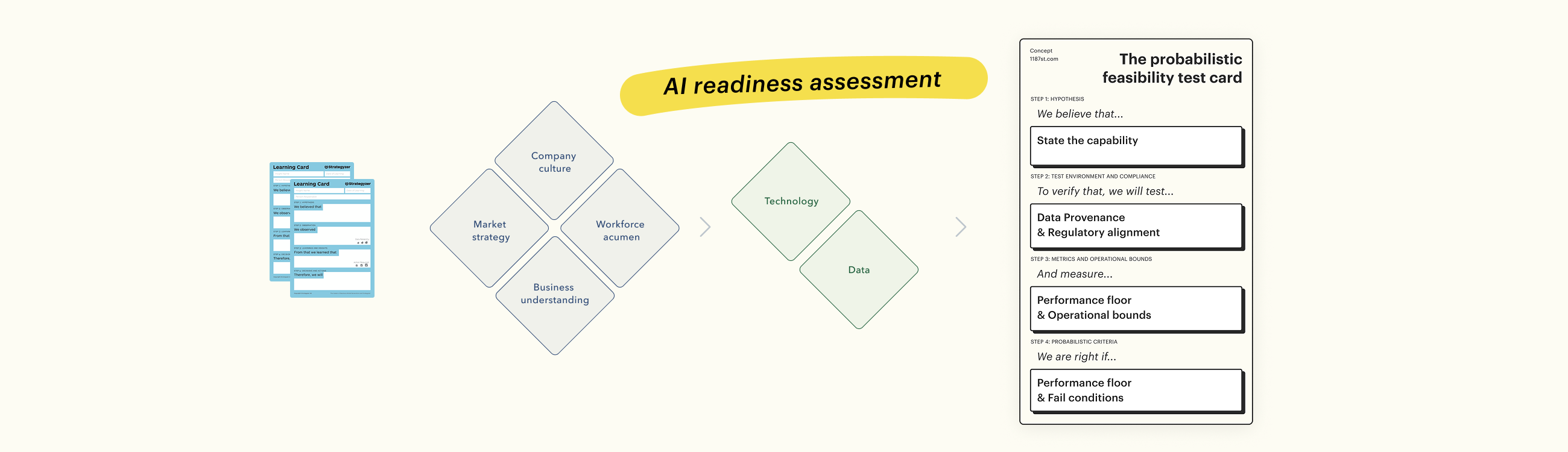
Validating feasibility test cards for AI systems in the Explore portfolio


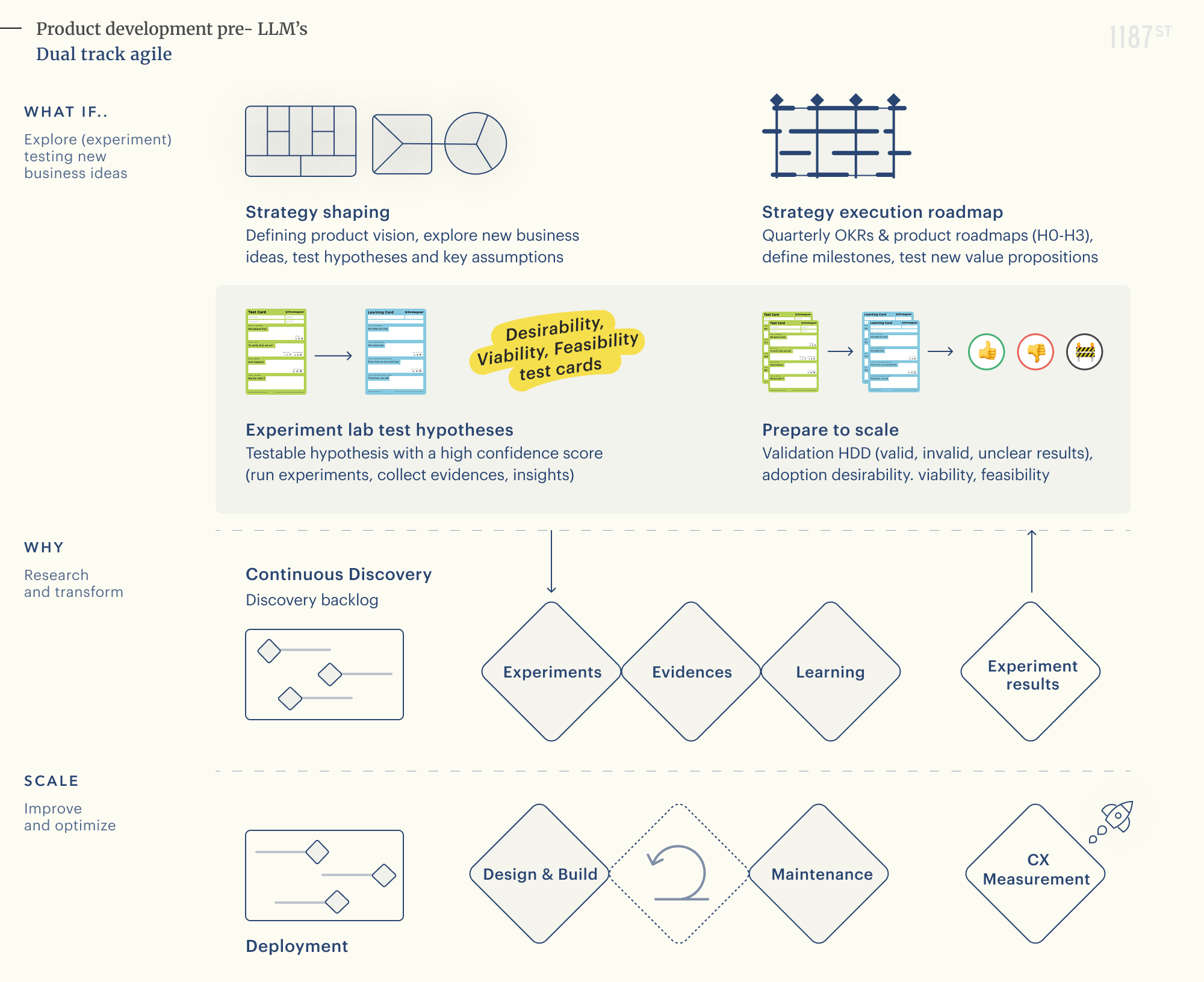
The current approach to testing business ideas in the Explore Portfolio of the Explore & Exploit portfolio strategy is fundamentally altered by the probabilistic nature of AI Systems. In the traditional SaaS landscape, feasibility was typically a binary assessment focused on whether a product could be built and shipped.
Validating business ideas in the Explore portfolio has historically relied on the same 4-step format across desirability, viability and feasibility test cards:
✦ Step 1: Hypothesis (We believe that..)
✦ Step 2: Test (To verify that, we will..)
✦ Step 3: Metric (And measure..)
✦ Step 4: Criteria (We are right if..)
AI systems, conversely, introduce a layer of performance uncertainty that demands iterative testing rather than a single technical validation. Organizations might technically be able to build something, but whether the model performs well enough to sustain a business model is an ongoing question.

The limitations of binary feasibility for integrated AI business ideas
Since AI is not an add-on but an integrated foundation when applicable in our future business ideas. Product teams face significant risk when moving from Explore to Exploit based solely on customer validation, market scalability, and answering the question of whether we can build it. Traditional portfolio theory bifurcates the world into two distinct phases:
✦ 'Search,' where success is measured by learning metrics (learning, hypotheses validated),
✦ 'Execution,' where success is measured by growth metrics (growth, adoption and delivery).
Traditional product discovery approaches asked three questions:
✦ Do customers want this? (Desirability)
✦ Can we make money from this? (Viability)
✦ Can we build and ship it? (Feasibility, typically a binary yes/no)
As-Is: Testing hypotheses with Feasibility test cards today
In current standard practice, the feasibility lens is tested through a uniform validation format alongside desirability and viability. In essence:
✦ The format captures the test hypothesis we are trying to validate:
"We believe that..." followed by the experiment design, measurement, and success criteria.
✦ When applied to technology, this usually results in proofs-of-concept (POCs) that validate purely technical capability
(e.g., "We believe we can connect to the GPT-5.2 API to summarize text" or "We believe we can architect a GraphRAG pipeline to extract complex liability clauses from PDFs.").
✦ The result is binary: if the connection works and text is generated, the test is marked "Validated," or as "Invalid" if it fails.
AI systems introduce a third dimension: Model Efficacy
This dimension establishes the critical link between technical reliability and commercial success, identifying exactly how often the system can fail before the business case becomes a liability.
Even if users love a product in a vibe-coded prototype, scaling cannot occur until model efficacy is validated. This creates a new governance requirement: Continuous model evaluation as a strategic function, not a QA checklist.
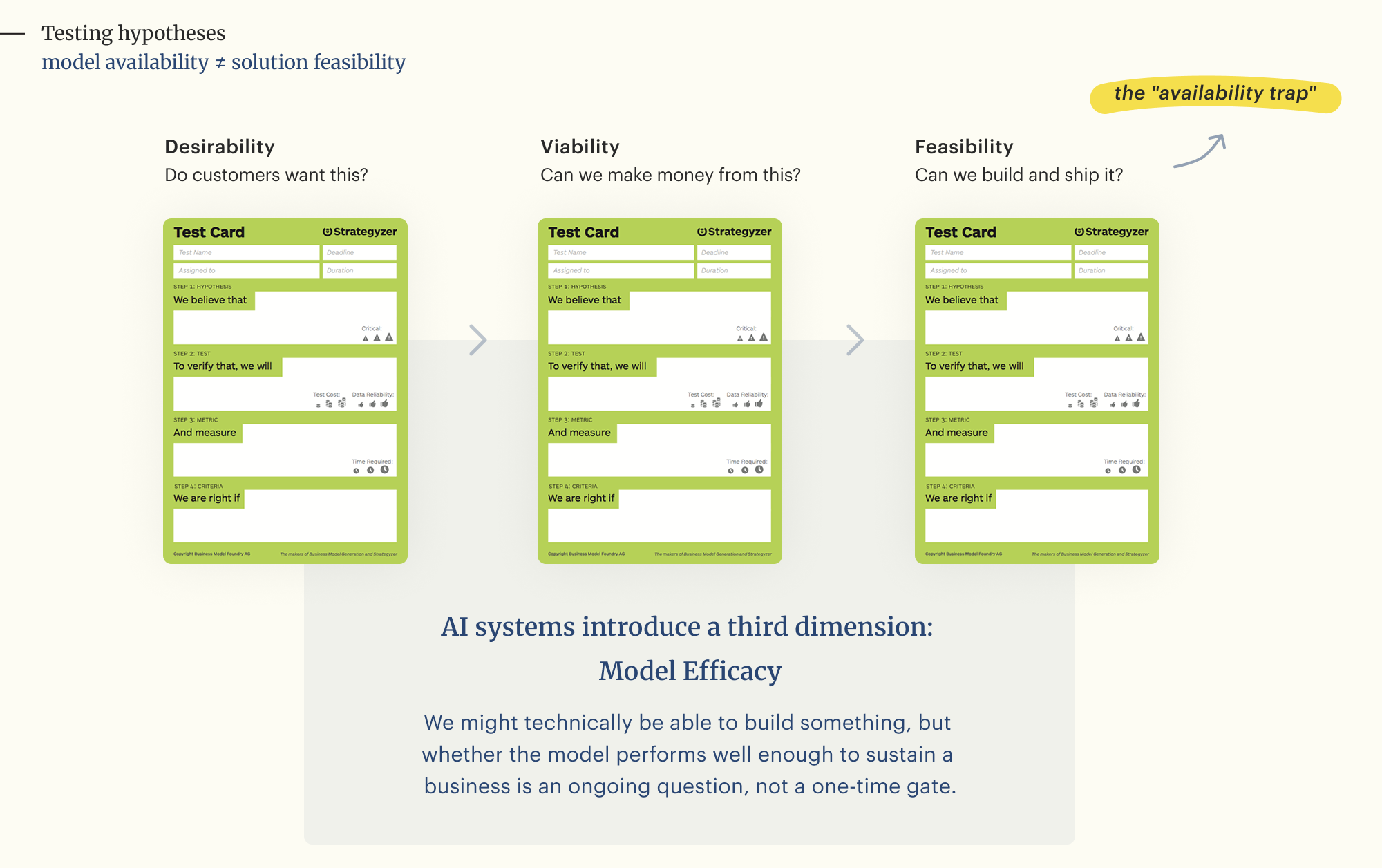
The concern: The "availability trap" risk with AI integrated business models
This approach creates a creates a critical blind spot for AI products where product teams confuse model availability with solution feasibility.
Product teams risk validating a "phantom POC" (a product that operates technically but relies on a model incapable of delivering reliable results). An AI system can be technically functional (it runs) but commercially fatal (it is only 60% of the 90% required accuracy thresholds to sustain the business model.
The current feasibility test card validates the existence of the engineering pipeline, yet it fails to prove that the input data holds the predictive patterns required to generate accurate outputs. Treating validation as a static checkpoint neglects the reality that guardrails are safety mechanisms rather than competence generators. If the raw model requires cost-prohibitive engineering chains or human intervention to function correctly, the product may technically work while failing the unit economics required for a viable business model.

Conducting an AI readiness assessment before feasibility testing
Sol Rashidi's "Your AI Survival Guide" presents Phase 1 of her six-phase framework as an analytical step to surface operational conditions that influence feasibility. The assessment prevents organizations from selecting growth narratives they cannot operationally support, avoiding POC purgatory disguised as progress.
This questionnaire serves as a gut-check before teams commit to a probabilistic feasibility test card. Within the Strategyzer Explore portfolio, desirability and viability testing naturally expose maturity signals across four dimensions:
1. Market understanding: Do you know your competitive landscape and where the disruption is coming from?
2. Business understanding: How well-defined are your current business processes and value drivers?
3. Workforce acumen: Does your team have the skills, or the willingness to learn, required for AI adoption?
4. Company culture: Is your organization risk-averse? Do you punish failure or embrace iteration?
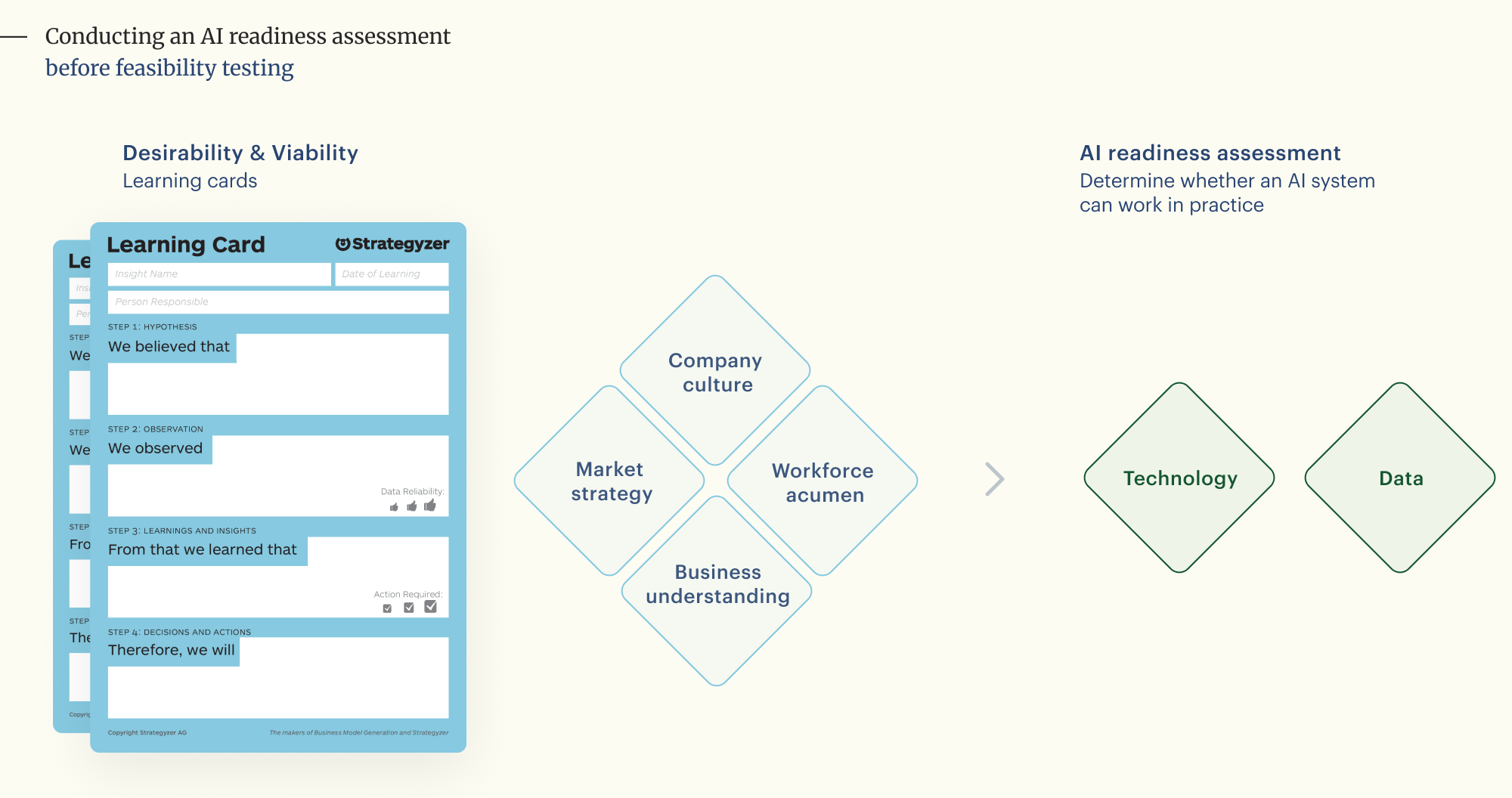
Only after those lenses produce evidence does feasibility testing begin. At that stage, the assessment focuses on two structural pillars that determine whether an AI system can work in practice:
5. Data: Is your data accessible, clean, and governed?
6. Technology: How modern and flexible is your current tech stack?
These dimensions map to Rashidi's strategy pillars, which establish the ceiling of what an organization can realistically pursue:
✦ Efficiency (cost reduction and automation),
✦ Effectiveness (improving accuracy),
✦ Productivity (workforce augmentation),
✦ Expert systems (scalable knowledge distribution), and
✦ Growth (new revenue models requiring full-stack maturity).
In my approach this AI readiness assessment does not restrict which business ideas can be explored.
It informs what feasibility must prove, providing the diagnostic context to understand whether the proposed solution requires data maturity, infrastructure upgrades, or performance thresholds that must be validated before moving from Explore to Exploit.
The evolution: The probabilistic feasibility test card
The adapted probabilistic feasibility test card explicitly structures the uncertainty of AI systems. It retains the hypothesis but modifies the execution fields to enforce precise definition around inputs and outputs.]

Adding model efficacy to the Explore validation framework
The focus expands from validating technical possibility to defining the performance floor required for the business model to survive. This adaptation introduces 5 critical constraints into the discovery process:
1. Data provenance covering inputs and signal
This constraint mandates the explicit definition of the data source before testing the engine. It proactively addresses the risk that AI models can silently degrade as underlying data distributions shift or as upstream model providers update their systems.
2. Performance floor for accuracy and precision
Specific Critical Thresholds replaces generic success criteria with specific "Critical Thresholds" for model performance (e.g., accuracy rates, error tolerances). It establishes the exact frequency of hallucinations, missed edge cases, and confident errors the business case can tolerate before the value proposition collapses.
3. Operational bounds for latency and cost
Setting a technical ceiling for latency and inference cost ensures the business model can scale. This parameter sets the maximum allowable time-to-response (e.g., <200ms) and compute cost per transaction (e.g., <$0.01) required for the business model to scale. Models that depend on expensive, heavy-compute architectures to achieve accuracy must fail feasibility if they violate these unit economic limits.
4. Fail conditions for stability and safety
Mapping the negative space reveals the specific failures that would destroy the business case regardless of overall accuracy. Since users rarely follow happy paths, this condition validates whether the model degrades gracefully or fails catastrophically when presented with unstructured phrasing.
5. Regulatory and ethical compliance
Assessing alignment with legal frameworks and responsible AI standards prevents the development of liability-prone models. Identifying use cases that rely on copyright-infringing data or violate privacy statutes like GDPR ensures strategic resources are protected before commitment.
Evaluating the cost of compliance across targeted jurisdictions determines whether a market remains commercially attractive. High remediation costs required to meet frameworks like the EU AI Act may render specific regions unprofitable despite high user demand, forcing early decisions on market exclusion or product pivots.
The probabilistic feasibility test card in practice
Case study: Allianz - Agentic hidden dependency risk analysis
Background: Allianz is a global insurance and financial services corporation offering a broad range of insurance, asset management and risk solutions worldwide.
Most important assumption: We believe that Allianz risk teams will identify and act on loss escalation risks earlier when they can see which policies depend on the same underlying supplier, system, or operational bottleneck, compared to using current risk reports.
Business idea: This business idea tests whether an agentic AI system can continuously discover and simulate shared dependencies across policies, making cascading loss risks visible early so risk teams can act before losses escalate. Helping Allianz identify systemic risk build-up earlier, before losses cascade, without relying on language interpretation.
The solution: Model-based AI system
✦ Learns hidden dependencies and correlations across large, high-dimensional numeric and relational data without predefined rules.
✦ Performs inference under uncertainty and adapts as portfolio structures change.
✦ It discovers non-obvious relationships and produces new, explainable insights for human decision-making, rather than executing fixed logic or workflows
Below is a side-by-side comparison: the as-is feasibility card and the probabilistic feasibility card for the same test hypothesis.
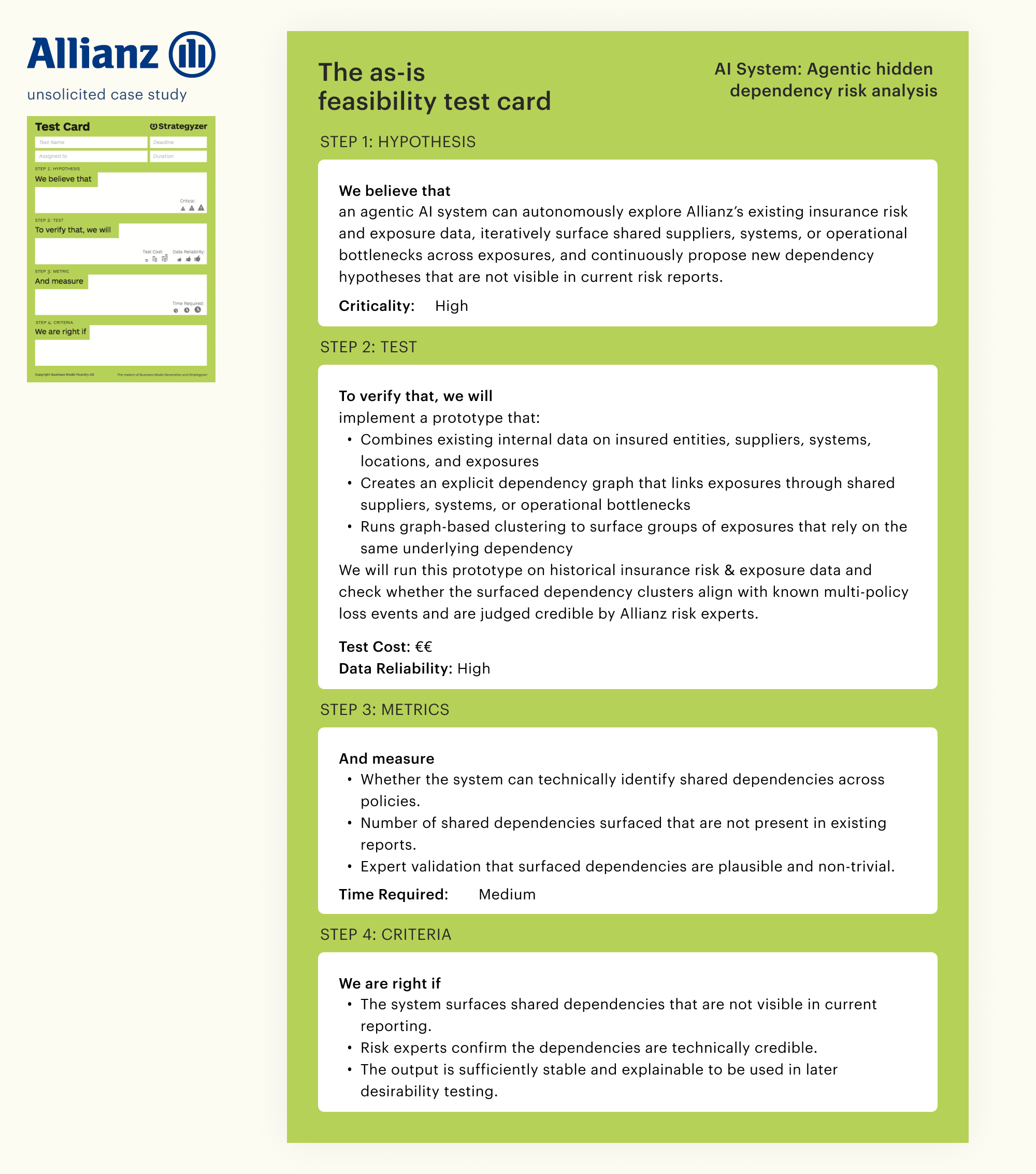
What the Allianz comparison reveals
The as-is feasibility test card would have validated that the dependency graph could be built. The probabilistic feasibility test card validates whether the graph performs well enough to sustain the business model.
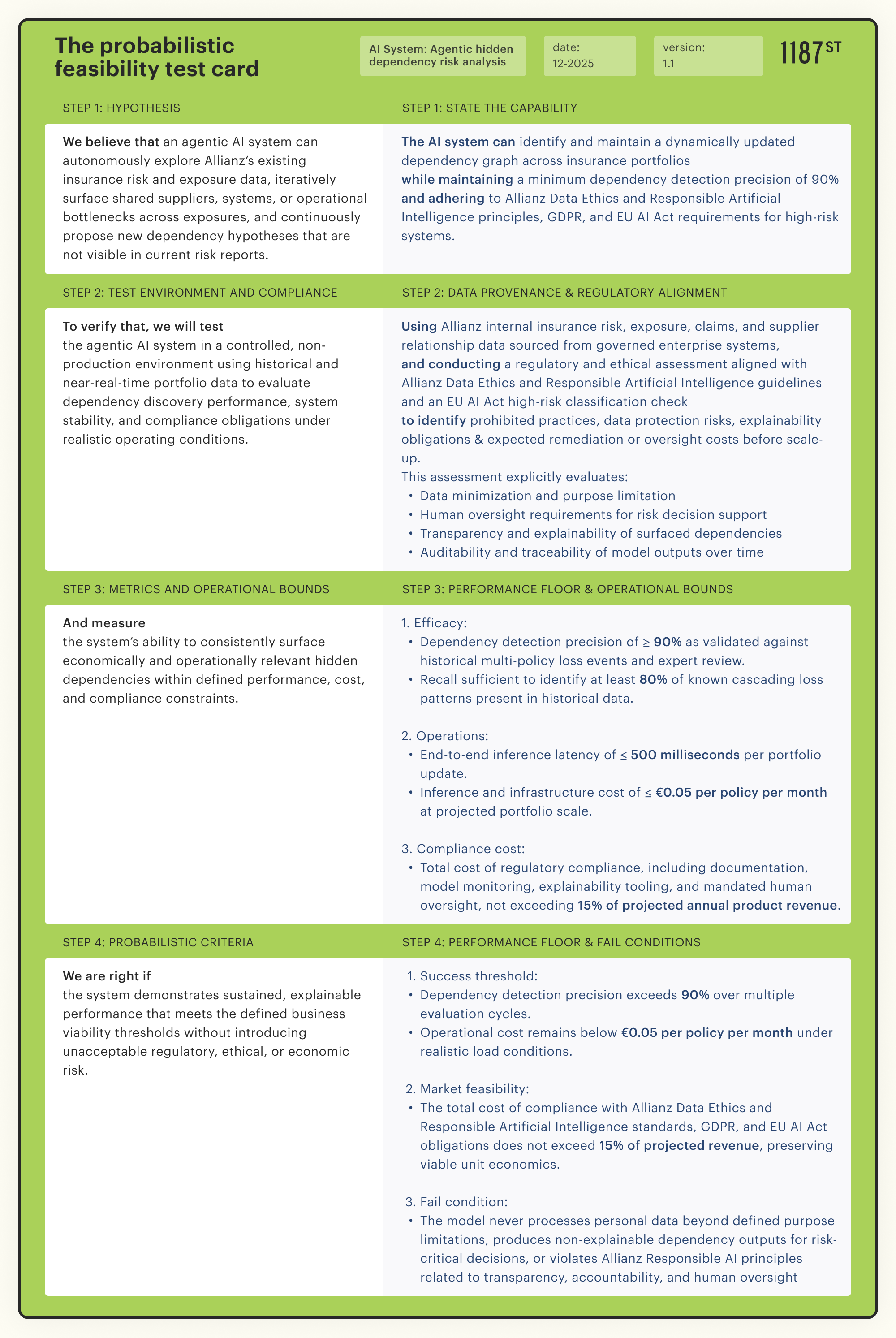
Three critical gaps become visible in the comparison:
1. The as-is feasibility test card treats accuracy as binary. It asks whether dependencies can be surfaced.
The probabilistic feasibility card asks whether they can be surfaced at 90% precision, the floor below which risk teams cannot trust the output enough to act.
2. The as-is feasibility test card ignores operational economics.
The probabilistic feasibility card demands proof that €0.05 per policy per month is achievable at scale. A model requiring €2.00 per policy validates technically while failing commercially.
3. The as-is feasibility test card defers technical AI compliance to later phases.
The probabilistic feasibility card front-loads the question: if meeting EU AI Act explainability requirements consumes 40% of projected revenue, the business idea fails feasibility regardless of model performance.
This shift moves from "can we build it" to "can we build it at the performance floor required for commercial viability," preventing phantom POCs from consuming Exploit resources. Product teams no longer graduate ideas that work in demos but collapse under production economics.
References: